
|
|
|
|
|
My research aims to enable robots to perform diverse and complex tasks in unstructured environments using deep learning. To achieve this, my lab and I develop scalable algorithms and systems for robot perception and control with the following focuses:
|
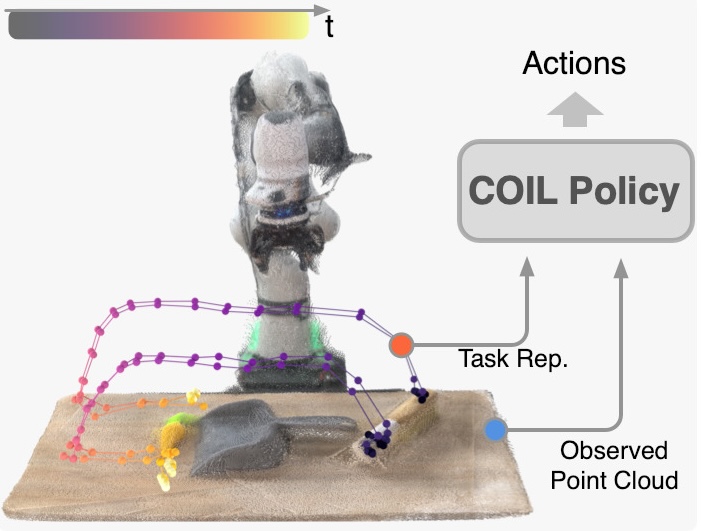
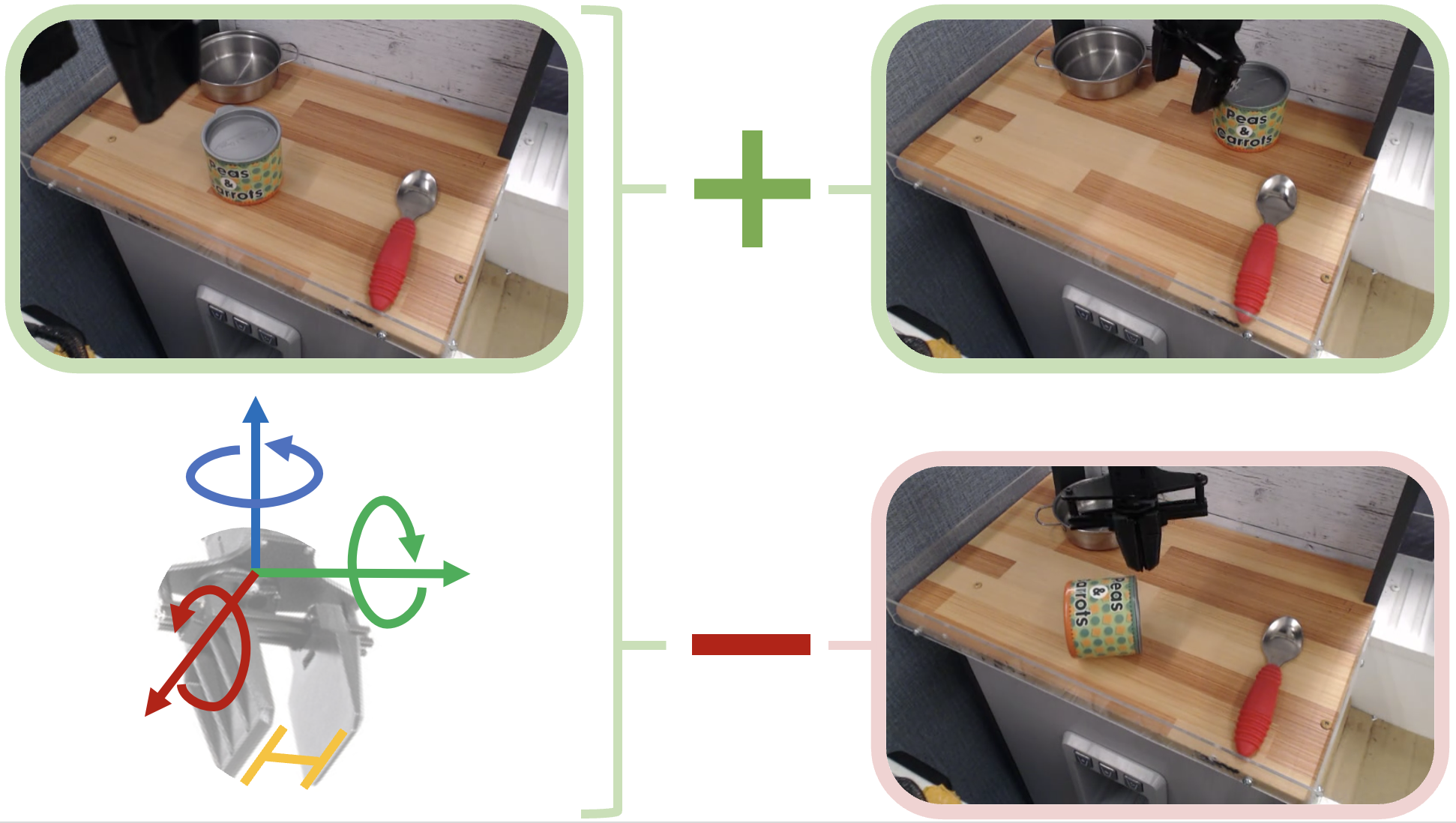
Correspondence-Oriented Imitation Learning: Flexible Visuomotor Control with 3D Conditioning
|
|
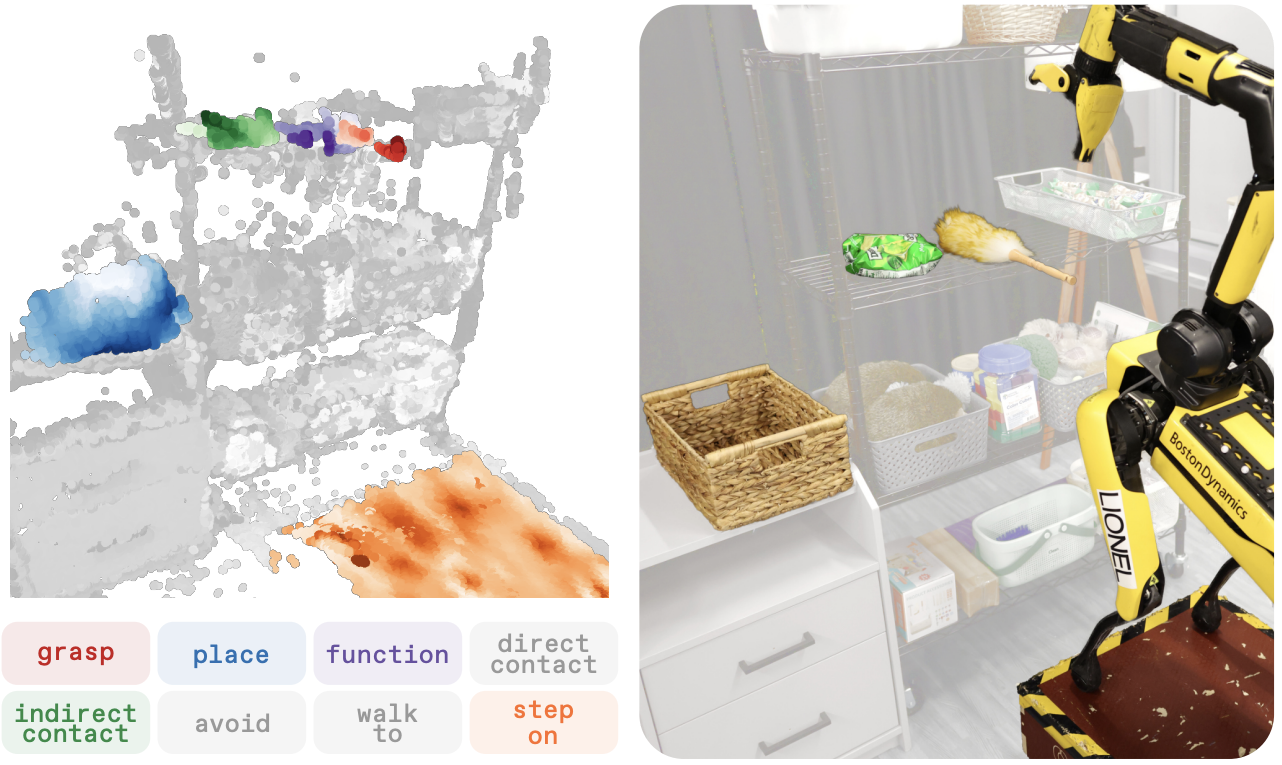
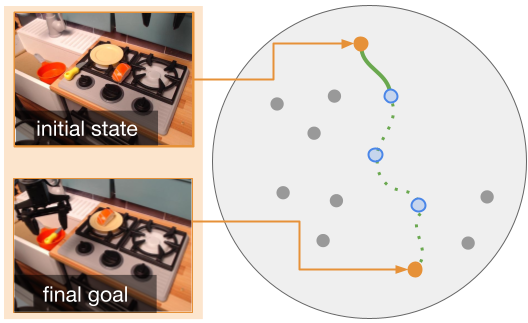
SAGA: Open-World Mobile Manipulation via Structured Affordance Grounding
|

|
Generate, Transfer, Adapt: Learning Functional Dexterous Grasping from a Single Human Demonstration
|

|
Planning-Guided Diffusion Policy Learning for Generalizable Contact-Rich Bimanual Manipulation
|

|
Should We Learn Contact-Rich Manipulation Policies from Sampling-Based Planners?
|

|
Versatile Loco-Manipulation through Flexible Interlimb Coordination
Conference on Robot Learning (CoRL) 2025 (Oral Presentation) |

|
Temporal Representation Alignment: Emergent Compositionality in Instruction Following with Successor Features
|
|
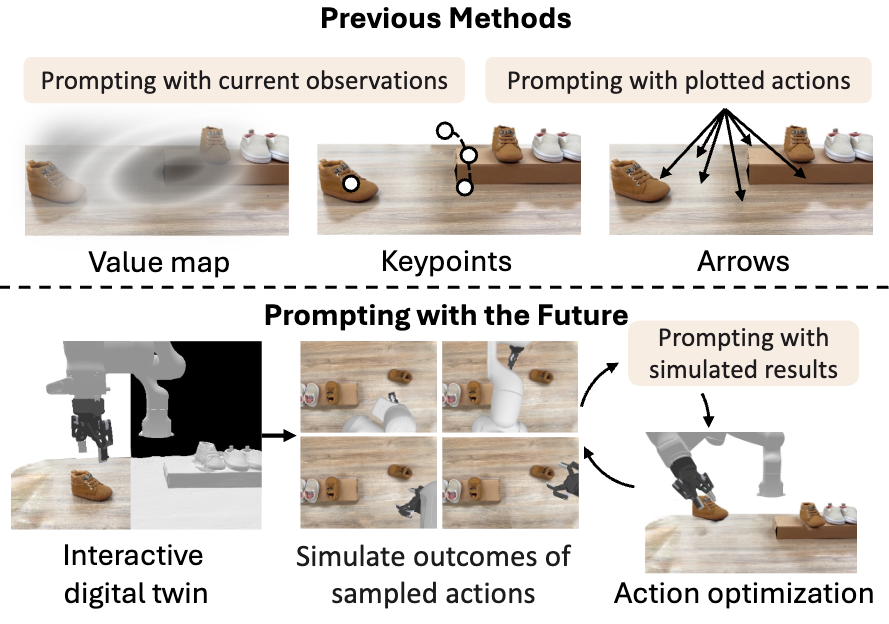
Prompting with the Future: Open-World Model Predictive Control with Interactive Digital Twins
|

|
Blox-Net: Generative Design-for-Robot-Assembly using VLM Supervision, Physics Simulation, and A Robot with Reset
|

|
KALIE: Fine-Tuning Vision-Language Models for Open-World Manipulation without Robot Data
|
|
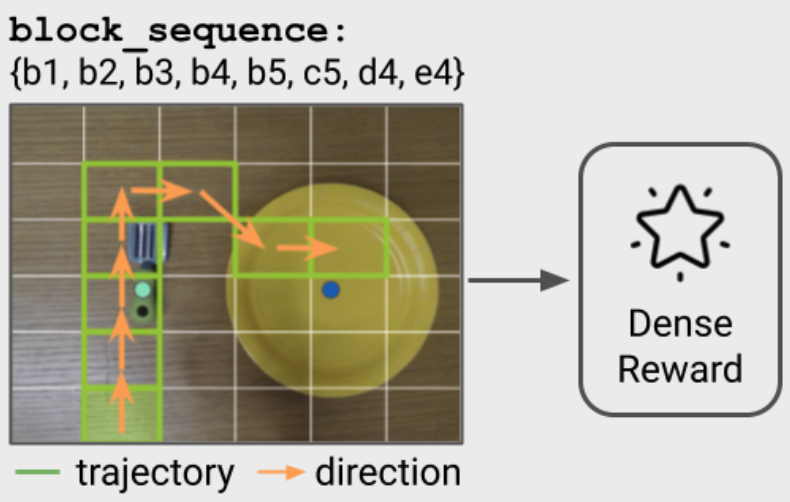
Affordance-Guided Reinforcement Learning via Visual Prompting
|

|
Policy Adaptation via Language Optimization: Decomposing Tasks for Few-Shot Imitation
|

|
Jacta: A Versatile Planner for Learning Dexterous and Whole-Body Manipulation
|

|
MOKA: Open-World Robotic Manipulation through Mark-Based Visual Prompting
|

|
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
|
|
Stabilizing Contrastive RL: Techniques for Offline Goal Reaching
|

|
Multi-Stage Cable Routing Through Hierarchical Imitation Learning
|

|
Goal Representations for Instruction Following: A Semi-Supervised Language Interface to Control
|

|
BridgeData V2: A Dataset for Robot Learning at Scale
|

|
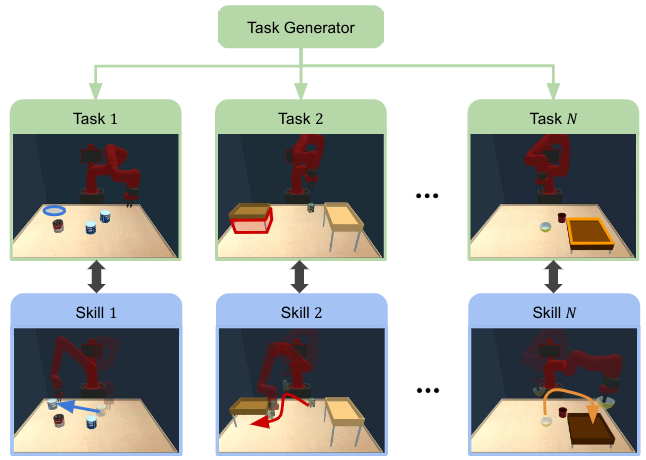
Active Task Randomization: Learning Robust Skills Via Unsupervised Generation of Diverse and Feasible Tasks
|
|
Generalization with Lossy Affordances: Leveraging Broad Offline Data for Learning Visuomotor Tasks
Conference on Robot Learning (CoRL) 2022 (Oral Presentation) |

|
Planning to Practice: Efficient Online Fine-Tuning by Composing Goals in Latent Space
|
|
Discovering Generalizable Skills via Automated Generation of Diverse Tasks
|
|
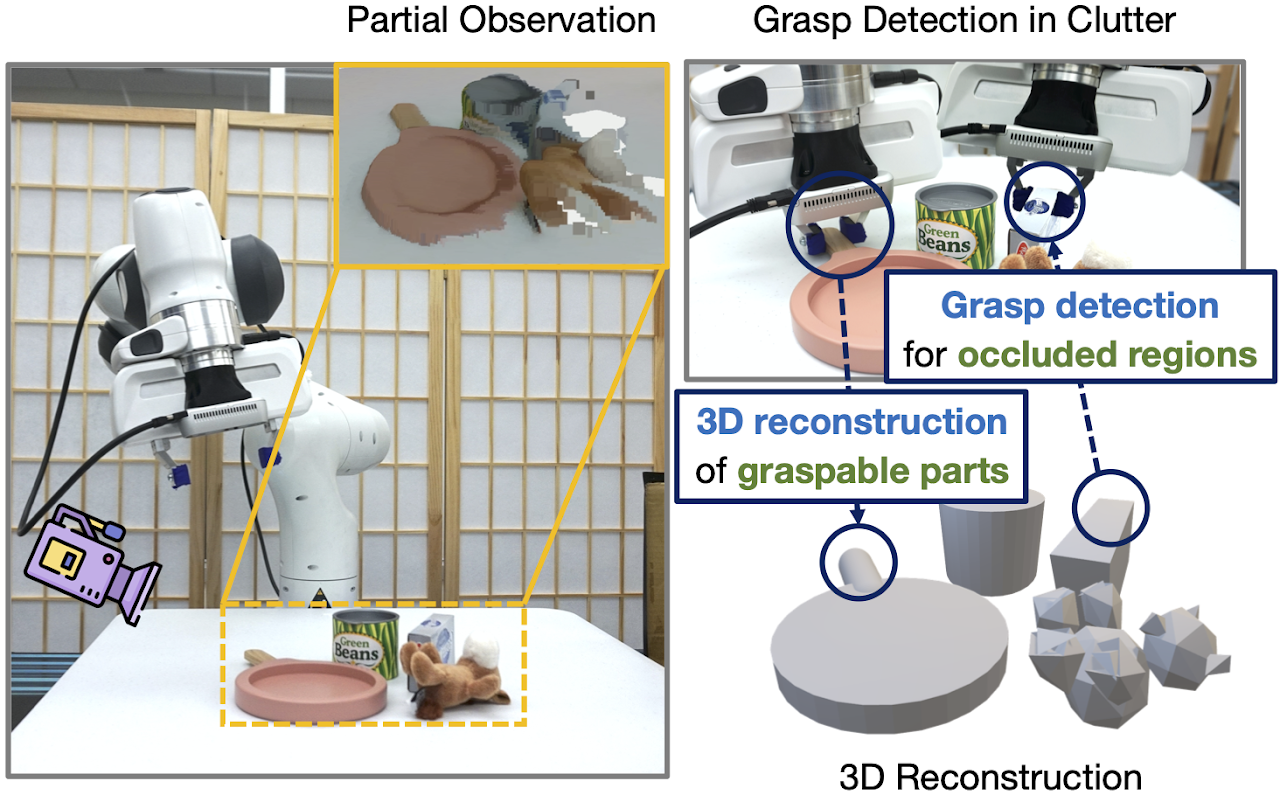
Synergies Between Affordance and Geometry: 6-DoF Grasp Detection via Implicit Representations
|

|
Adaptive Procedural Task Generation for Hard-Exploration Problems
|
|
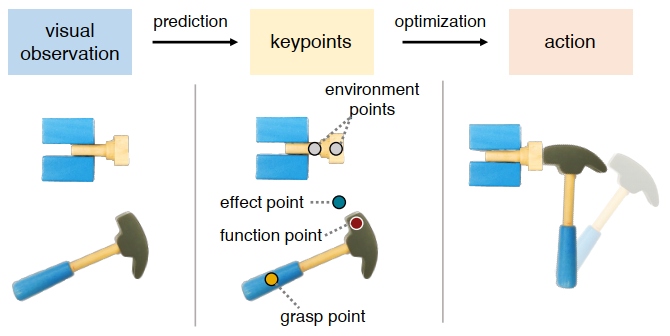
KETO: Learning Keypoint Representations for Tool Manipulation
|

|
Dynamics Learning with Cascaded Variational Inference for Multi-Step Manipulation
Conference on Robot Learning (CoRL) 2019 (Oral Presentation) |
|
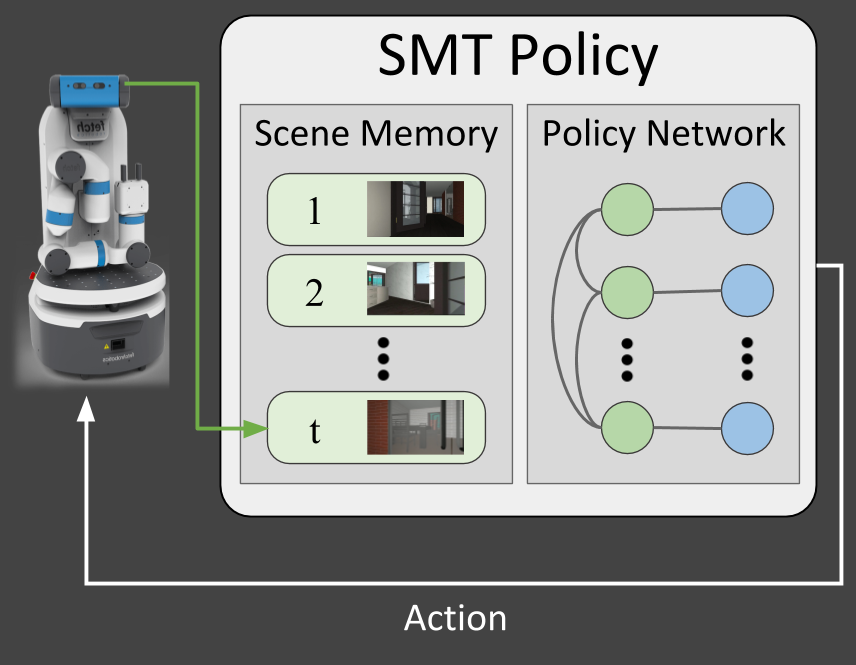
Scene Memory Transformer for Embodied Agents in Long-Horizon Tasks
|

|
Learning Task-Oriented Grasping for Tool Manipulation from Simulated Self-Supervision
|
|
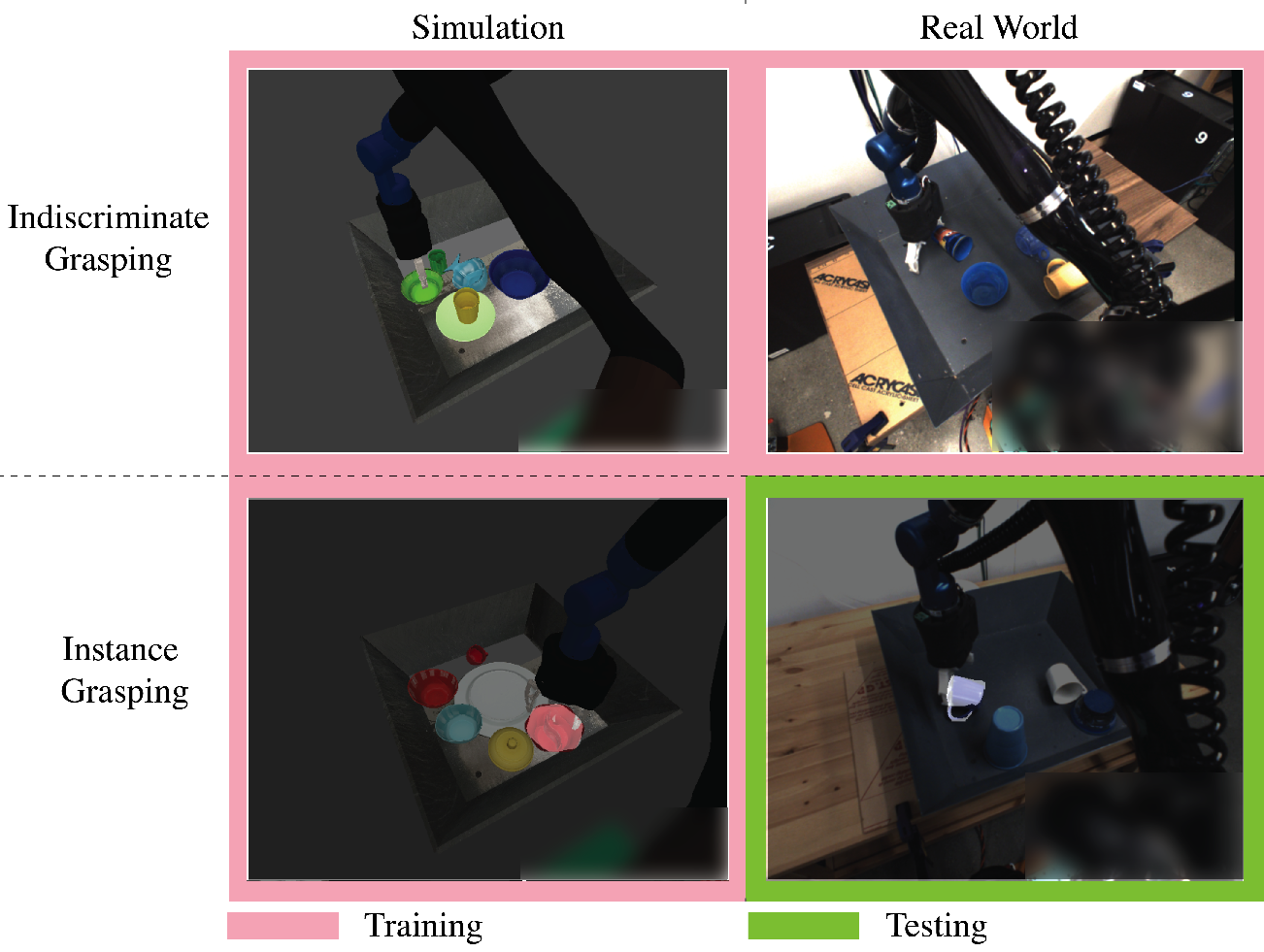
Multi-Task Domain Adaptation for Deep Learning of Instance Grasping from Simulation
|
|
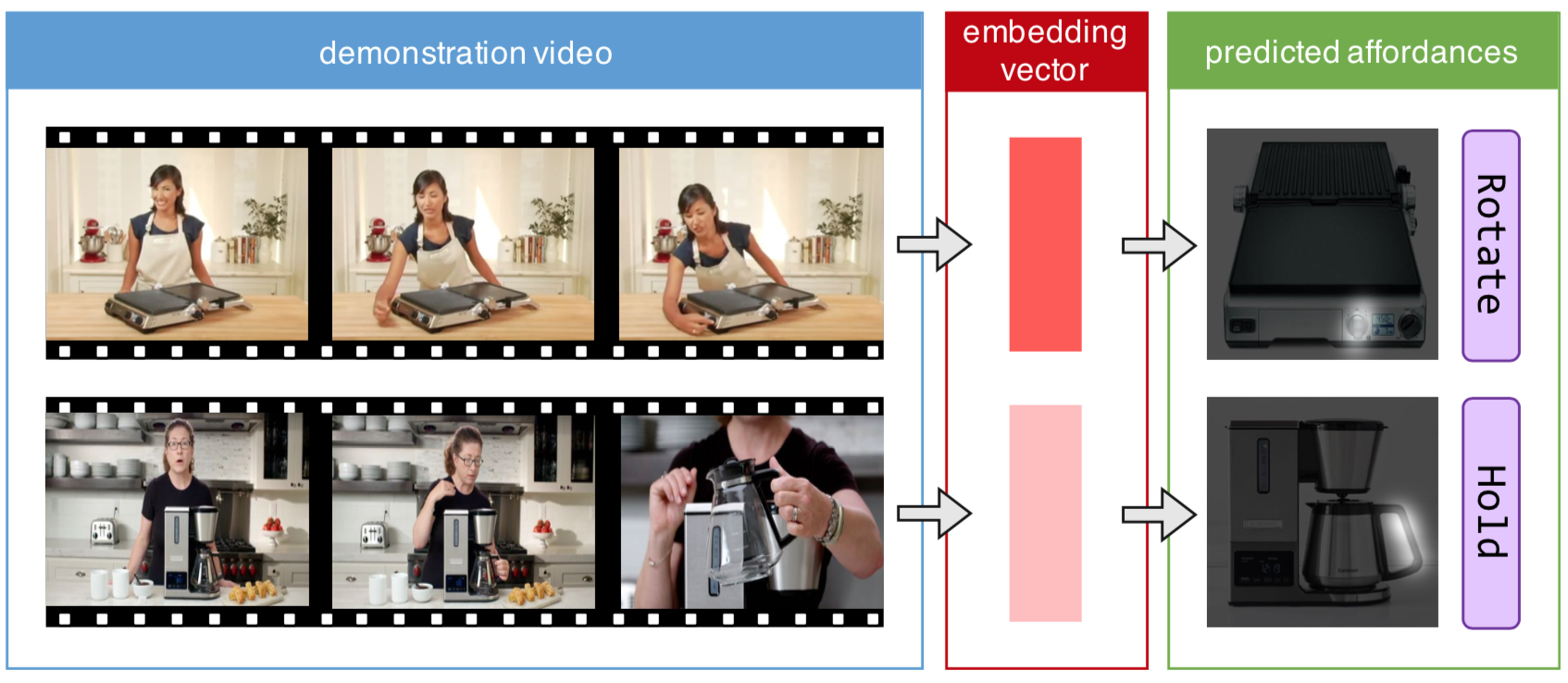
Demo2Vec: Reasoning Object Affordances from Online Videos
|
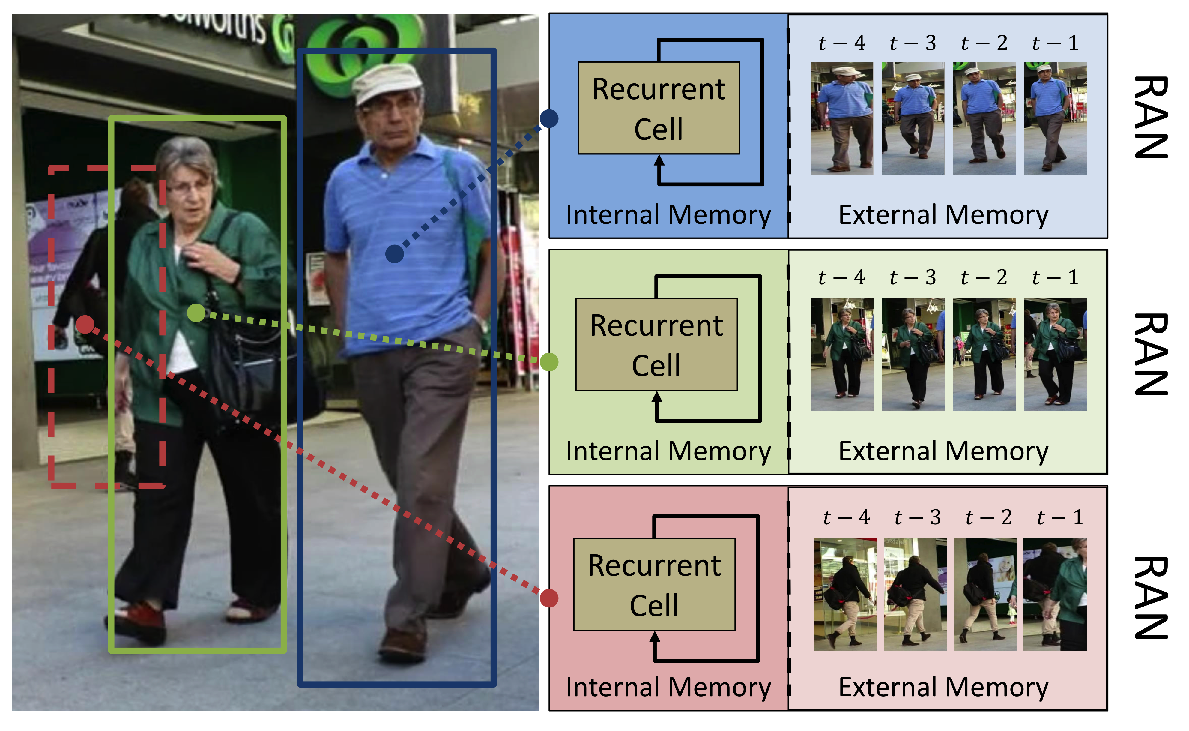
|
Recurrent Autoregressive Networks for Online Multi-Object Tracking
|

|
DeLay: Robust Spatial Layout Estimation for Cluttered Indoor Scenes
|